 |
libdl
0.0.1
Simple yet powerful deep learning
|
|
libdl
0.0.1
Simple yet powerful deep learning
|
Public Member Functions | |
| TransformerEncoder (TransformerEncoder &other)=delete | |
| TransformerEncoder (TransformerEncoder &&other)=delete | |
| TransformerEncoder (TransformerConf conf) noexcept | |
| virtual TensorPtr | forward (TensorPtr input) override |
| TensorPtr | scaledDotProductAttention (TensorPtr query, TensorPtr key, TensorPtr value) noexcept |
| Implements the scaled dot-product attention. | |
| TensorPtr | multiHeadAttention (TensorPtr query, TensorPtr key, TensorPtr value) noexcept |
| Implements the transformer's multi-head attention. | |
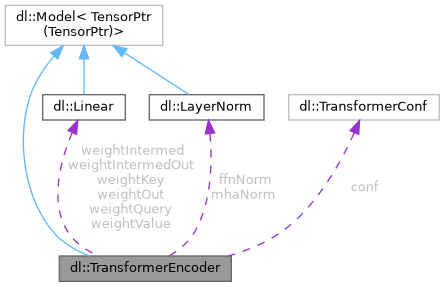
Public Attributes | |
| TransformerConf | conf |
| dl::Linear | weightQuery |
| dl::Linear | weightKey |
| dl::Linear | weightValue |
| dl::Linear | weightOut |
| dl::Linear | weightIntermed |
| dl::LayerNorm | mhaNorm |
| dl::Linear | weightIntermedOut |
| dl::LayerNorm | ffnNorm |
| const float | dimKeysInvSqrt |
| The precomputed inverse square root of dimKeys. | |
Definition at line 36 of file transformer.hpp.
|
noexcept |
Implements the transformer's multi-head attention.
Multi-head attention is chapter 3.2.2 in the transformer paper [8]. Let \(W_i^Q, W_i^K\in \mathbb{R}^{d_\text{model} \times d_k}, W_i^V \in \mathbb{R}^{d_\text{model} \times d_v}\) denote the query, key and value matrix of the i-th head respectively for \(1\leq i \leq h\), where \(h\) is the total number of heads. Further, let \(W^O\) denote the output linearity. Multi-head attention is defined as the concatinated attention of each attention head:
\[ \text{MHA}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)\cdot W^O \text{ with } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V), \]
where "Attention" denotes scaledDotProductAttention (TransformerEncoder::scaledDotProductAttention).
\[\text{MHA}(Q, K, V) = \text{Concat}( \text{Attention}(QW_1^Q+b_1^Q, KW_1^K+b_1^K, VW_1^V+b_1^V), \dots)\cdot W^O + b^O.\]
| query | |
| key | |
| value |
|
noexcept |
Implements the scaled dot-product attention.
Scaled dot-product attention is Eq. (1) in the transformer paper [8] :
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V.\]
| value | |
| key | |
| query |
| TransformerConf dl::TransformerEncoder::conf |
Definition at line 38 of file transformer.hpp.
| const float dl::TransformerEncoder::dimKeysInvSqrt |
The precomputed inverse square root of dimKeys.
This is the precomputed normalization factor \(\sqrt{d_k}^{-1}\) used in the scaled dot-product attention.
Definition at line 62 of file transformer.hpp.
| dl::LayerNorm dl::TransformerEncoder::ffnNorm |
Definition at line 48 of file transformer.hpp.
| dl::LayerNorm dl::TransformerEncoder::mhaNorm |
Definition at line 45 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightIntermed |
Definition at line 44 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightIntermedOut |
Definition at line 47 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightKey |
Definition at line 41 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightOut |
Definition at line 43 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightQuery |
Definition at line 40 of file transformer.hpp.
| dl::Linear dl::TransformerEncoder::weightValue |
Definition at line 42 of file transformer.hpp.